New Garbage Collector
Introduction
The following design document describes the the new garbage collector (GC) to be introduced with LuaJIT 3.0. This document is very much a work in progress right now. Anything may change for the actual implementation. No code is available, yet.
The purpose of this document is to gather early feedback on all design aspects and to present the planned work to sponsors.
Note to potential sponsors: This feature is in need of sponsorship! Work on LuaJIT 3.0 probably won't start until I'm able to get full covenants for this and other planned new features. Please refer to the LuaJIT Sponsorship Page. Thank you!
You probably need to have at least some background knowledge on garbage collection algorithms to fully enjoy the following document. There are plenty of books, research papers and other freely available online resources for this. A good start would be the Wikipedia article on Garbage Collection.
Rationale
The garbage collector used by LuaJIT 2.0 is essentially the same as the Lua 5.1 GC. There are some minor refinements for write barriers and a couple of speed optimizations. But the basic algorithms and data structures are unchanged.
The current garbage collector is relatively slow compared to implementations for other language runtimes. It's not competitive with top-of-the-line GCs, especially for large workloads. The main causes for this are the independent memory allocator, cache-inefficient data structures and a high number of branch mispredictions. The current GC design is a dead end when it comes to further performance tuning.
What's needed is a complete redesign from scratch with the following goals:
- It must be a very fast, top-of-the-line, highly competitive garbage collector.
- It must be able to sustain high throughput and large workloads.
- But it should run well with a reasonable minimum amount of memory.
- It needs to be incremental (but not real-time) with very low latencies.
- It must be non-copying, due to various constraints in the Lua/C API.
- But it needs to tightly control fragmentation.
- It doesn't need to be concurrent, since Lua states are completely independent.
- It would be nice to have an (automatic) generational mode for certain workloads.
- It should be optimized for operation with the combination of an interpreter and a JIT compiler.
- It needs extra debugging and profiling support, since regular tools (Valgrind memcheck et al) won't be effective anymore.
- Overall implementation complexity should be kept as low as possible.
This leads to the following implementation constraints:
- The memory allocator and the garbage collector must be tightly integrated.
- Plain linked lists should be avoided as far as possible.
- Data structures should be optimized for high-speed allocation, traversal, marking and sweeping.
- Object metadata, such as mark & block info should be segregated.
- Huge objects should be segregated.
- Traversable and non-traversable objects should be segregated.
- Traversals should be linear or at least have strong locality.
- Memory should be requested and returned from or to the operating system in big blocks only.
It's decidedly not a goal to create a highly complex and experimental garbage collector that incidentally solves the world's hunger problems, too, but needs more memory than Eclipse to run smoothly. :-)
The new garbage collector should be based on well-researched and proven algorithms, together with a couple of thoroughly evaluated innovations, where appropriate. The real innovation should be in the specific mix of techniques, forming a coherent and well-balanced system, with meticulous attention to detail and relentless optimization for performance.
Overview
The new garbage collector is an arena-based, quad-color incremental, generational, non-copying, high-speed, cache-optimized garbage collector.
Memory is requested from the operating system in big aligned memory blocks, called arenas. Arenas are split into 16-byte sized cells. One or more cells make up a block, which is the basic memory unit used to store objects and related object data. All objects inside an arena are either traversable or not. The block and mark bitmaps are kept in the metadata area of each arena, with a metadata overhead of 1.5%. Huge blocks are located in separate memory areas.
Pointers to arenas, huge blocks, interned strings, weak tables, finalizers, etc. are held in dedicated, cache-efficient data structures which minimize branch mis-predictions. E.g. hashes, unrolled linked lists or trees with high fan-out.
The allocator switches on-the-fly from a bump allocator to a segregated-fit, best-fit allocator with bounded search, depending on fragmentation pressure.
The collector is a quad-color, incremental mark & sweep collector with very low latency. Traversals are local to an arena and exhibit high cache locality. Arenas with non-traversable objects don't even need to be considered. Object marking and the ultra-fast sweep phase only work on metadata to reduce cache pressure. The sweep phase brings neither live nor dead object data back into the cache.
The write barrier of the incremental GC is very cheap and rarely triggers. A sequential store buffer (SSB) helps to further reduce overhead. The write barrier check can be done with only 2 or 3 machine instructions. The JIT compiler can eliminate most write barriers.
The collector automatically switches between a regular mode and a generational mode, depending on workload characteristics.
GC Algorithms
This is a short overview of the different GC algorithms used in Lua 5.x and LuaJIT 1.x/2.0 as well as the proposed new GC in LuaJIT 3.0.
All of these implementations use a tracing garbage collector (#) with two basic phases:
- The mark phase starts at the GC roots (e.g. the main thread) and iteratively marks all reachable (live) objects. Any objects that remain are considered unreachable, i.e. dead.
- The sweep phase frees all unreachable (dead) objects.
Any practical GC implementation has a couple more phases (e.g. an atomic phase), but this is not relevant to the following discussion. To avoid a recursive algorithm, a mark stack or mark list can be used to keep track of objects that need to be traversed.
Note that most of the following is just describing well-established techniques. Please refer to the literature on garbage collection for details.
(#) 'Tracing' in this context means it's tracing through the live object graph, as opposed to a reference counting garbage collector, which manages reference counts for each object. The terminology is not related to the concept of a trace compiler.
Two-Color Mark & Sweep
This is the classic (non-incremental) two-color mark & sweep algorithm:
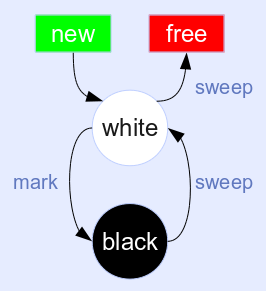
Newly allocated objects are white. The mark phase turns all reachable objects black. The sweep phase frees all white (unreachable) objects and flips the color of all black (surviving) objects back to white.
The main drawback of this algorithm is that the mutator (your running program code) cannot run interleaved with the collector. A collection cycle has to be completely finished, which means the algorithm is non-incremental (atomic collection).
There are various optimizations, e.g. the meaning of the two colors can be switched after each GC cycle. This saves the color flip in the sweep phase. You can find plenty of variations in the literature.
This is the GC algorithm used by Lua 5.0. All objects are kept in a linked list, which is processed during the mark and sweep phases. Objects that have been marked and need to be traversed are chained in a separate mark list.
Tri-Color Incremental Mark & Sweep
This is Dijkstra's three-color incremental mark & sweep algorithm:
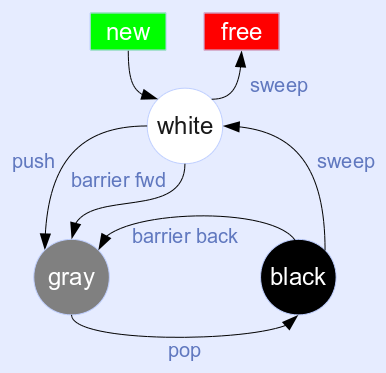
Newly allocated objects are white. The mark phase starts at the GC roots. Marking a reachable object means flipping the color of it from white to gray and pushing it onto a gray stack (or re-chaining it onto a gray list). The gray stack is iteratively processed, removing one gray object at a time. A gray object is traversed and all objects reachable from it are marked, like above. After an object has been traversed, it's turned from gray to black. The sweep phase works just like the two-color algorithm above.
This algorithm is incremental: the collector can operate in small steps, processing only a couple of objects from the gray stack and then let the mutator run again for a while. This spreads out the GC pauses into many short intervals, which is important for highly interactive workloads (e.g. games or internet servers).
But there's one catch: the mutator might get in the way of the collector and store a reference to a white (unprocessed) object at a black (processed) object. This object would never be marked and will be freed by the sweep, even though it's clearly still referenced from a reachable object, i.e. it should be kept alive.
To avoid this scenario, one has to preserve the tri-color invariant: a black object may never hold a reference to a white object. This is done with a write barrier, which has to be checked after every write. If the invariant has been violated, a fixup step is needed. There are two alternatives:
- Either turn the black object gray and push it back onto the gray stack. This is moving the barrier "back", because the object has to be reprocessed later on. This is beneficial for container objects, because they usually receive several stores in succession. This avoids a barrier for the next objects that are stored into it (which are likely white, too).
- Or immediately mark the white object, turning it gray and push it onto the gray stack. This moves the barrier "forward", because it implicitly drives the GC forward. This works best for objects that only receive isolated stores.
There are many optimizations to turn this into a practical algorithm. Here are the most important:
- Stacks should always be kept gray and re-traversed just before the final sweep phase. This avoids a write barrier for stores to stack slots, which are the most common kind of stores.
- Objects which have no references to child objects can immediately be turned from white to black and don't need to go through the gray stack.
- The sweep phase can be made incremental by using two whites and flipping between them just before entering the sweep phase. Objects with the 'current' white need to be kept. Only objects with the 'other' white should be freed.
This is the GC algorithm used by Lua 5.1/5.2 and LuaJIT 1.x/2.0. It's an enhancement of the linked list algorithm from Lua 5.0. Tables use backward barriers, all other traversable objects use forward barriers.
LuaJIT 2.0 further optimizes the write barrier for tables by only checking for a black table, ignoring the color of the stored object. This is faster to check and still safe: the write barrier may trigger more often, but this does no harm. And it doesn't matter in practice, since GC cycles progress very fast and have long pauses in-between, so objects are rarely black. Also stored objects usually are white, anyway.
Quad-Color Optimized Incremental Mark & Sweep
The quad-color algorithm is a refinement of the tri-color algorithm:
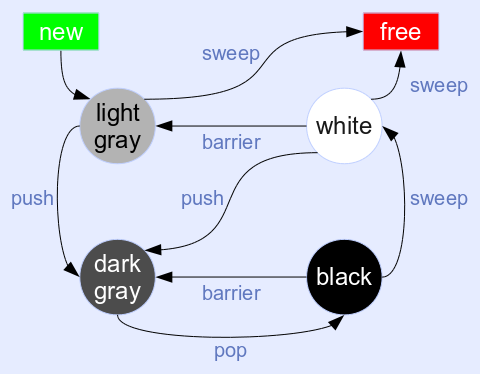
There's a problem with the tri-color algorithm for backward barriers: the write barrier checks can get expensive if mark bits are not inline in the object itself. But one has to do an exact check for a black object before turning it gray again when the barrier triggers. Alas, the mark bits (white vs. black) are segregated in the new GC, only the gray bit is inline in the object.
Just checking for 'not gray' is not a good idea: the write barrier would be triggered for both white and black objects, always turning them gray on the first write. This is especially bad for white objects during GC pauses, as lots of gray objects may needlessly accumulate in the gray stack.
The solution is to introduce a fourth color, splitting up gray into light-gray and dark-gray. Newly allocated traversable objects are light-gray: the mark bit is white, the gray bit is set. A new object is usually written to immediately after allocation. The write barrier only checks for a cleared gray bit and doesn't trigger in this case.
When the object is marked during the mark phase, it's turned dark-gray (mark bit turned black) and pushed onto the gray stack. In case it's unreachable, the sweep phase can free a light-gray object like any other object marked white.
Dark-gray objects are turned black after traversal (clearing the gray bit) and turned white after sweeping. The write barrier may trigger during this short period and move the barrier back by turning it dark-gray again.
An object that survived one GC cycle is turned white like all other survivors. In case the object is written to after that, it's turned light-gray again. But this doesn't push the object onto the gray stack right away! In fact, only the gray bit needs to be flipped, which avoids further barriers as explained above.
The main advantage of the quad-color algorithm is the ultra-cheap write barrier: just check the gray bit, which needs only 2 or 3 machine instructions. And due to the initial coloring and the specific color transitions, write barriers for e.g. tables are hardly ever triggered in practice. The fast path of the write barrier doesn't need to access the mark bitmap, which avoids polluting the cache with GC metadata while the mutator is running.
The quad-color algorithm can easily fall back to the tri-color algorithm for some traversable objects by turning them white initially and using forward write barriers. And there's an obvious shortcut for non-traversable objects: marking turns a white object black right away, which touches the mark bitmap only. Since these kind of objects are in segregated arenas, they don't need to be traversed and their data never needs to be brought into the cache during the mark phase.
This is the GC algorithm to be used by LuaJIT 3.0. Objects and the segregated metadata is managed in arenas (and not in linked lists).
There are various other GC algorithms that use more than the standard colors, e.g. two whites (see above). However none of them use the colors like this algorithm does. Also, a search for a "quad-color" GC (or variations) does not turn anything up. In the absence of evidence to the contrary, I (Mike Pall) hereby claim to have invented this algorithm. Please notify me immediately, if you disagree. As with all research results from my work on LuaJIT, I hereby donate the related intellectual property to the public domain. So please use it, share it and have fun!
Generational GC
The standard approach to generational GCs only works with a copying GC:
- Use separate memory spaces for each generation (2 or more, typically 3).
- New objects are allocated into the space dedicated to the youngest generation.
- The sweep phase is replaced with a copy phase, which copies the survivors of a GC cycle into an older generation. The remaining space can simply be emptied after that.
- Only the oldest generation has to use a traditional sweep phase or a mark & compact collector.
Obviously, this approach doesn't work for a non-copying GC. But the main insights behind a generational GC can be abstracted:
- Minor collections only take care of newly allocated objects.
- Major collections deal with all objects, but are run much less often.
The basic idea is to modify the sweep phase: free the (unreachable) white objects, but don't flip the color of black objects before a minor collection. The mark phase of the following minor collection then only traverses newly allocated blocks and objects written to (marked gray). All other objects are assumed to be still reachable during a minor GC and are neither traversed, nor swept, nor are their marks changed (kept black). A regular sweep phase is used if a major collection is to follow.
The generational mode of the collector is automatically triggered by workloads with a high death rate for young allocations. Running (say) five minor collections that deal only with young allocations plus one major collection ought to be cheaper than running (say) two major collections in the same time span. And the maximum memory usage should be lower, too. The collector returns to the regular, non-generational mode, in case these assumptions turn out not to be true.
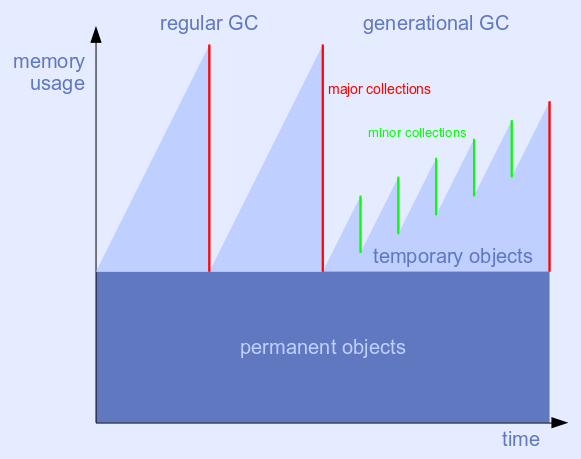
The image shown is greatly simplified: the allocation and survivor rates are constant; permanent objects don't change; collections are atomic.
Arenas
An arena is a big, specially aligned memory block. Arenas are requested directly from the operating system using system-specific code. A generic memory management API is offered for non-standard operating systems or for embedded use. A simple 'one-fixed-block' memory manager is available as a build-time option.
All arenas have the same size and they are naturally aligned to their size. E.g. 64 KB-sized arenas have addresses ending with 16 zero bits. This has two advantages:
- Aligned arenas can be densely packed and do not cause any extra memory fragmentation issues for the operating system.
- The metadata area of its arena can be derived from any interior pointer simply by masking off the lowest bits of the address.
All objects inside an arena are either traversable or not. Arenas with only non-traversable objects obviously don't need to be traversed at all. And there's no need to store an object type inside of those objects either.
The arena size can be any power of two from 64 KB up to 1 MB. The optimal arena sizes for each OS and CPU still needs to be determined experimentally. Memory managers may request even bigger blocks from the OS (e.g. 2 MB or 4 MB for huge page support) and split them up.
1/64th of the space of each arena is dedicated to the metadata area, leading to a fixed overhead of 1.5%. The metadata area is located at the start of each arena. The remaining space is used for the data area. The following image shows the general layout of an arena:
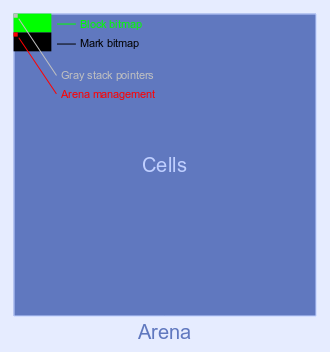
Cells and Blocks
The data area of each arena is split up into 16-byte sized cells. One or more cells make up a block, which is the basic memory unit used to store objects and related object data.
The index of a cell (or a block) can be derived from its starting address: mask out the top bits that identify the arena and shift the resulting relative address by 4 bits to the right to get the cell index.
Cell indices do not start at zero, because the first indices would point to the metadata area. A cell index always fits into 16 bits, because the maximum arena size is 1 MB.
Block & Mark Bitmaps
The block and mark bitmaps make up the majority of the space in the metadata area of each arena. The two bitmaps are segregated for better cache behavior. Every cell has an associated bit in the block bitmap and the mark bitmap. The bit index in each bitmap corresponds to the cell index.
The two bitmaps determine the blocks of an arena and their status:
| Block | Mark | Meaning |
|---|---|---|
| 0 | 0 | Block extent |
| 0 | 1 | Free block |
| 1 | 0 | White block |
| 1 | 1 | Black block |
This is a differential encoding: the type of the block (free, white or black) is determined by its first cell. A block can span multiple cells, it's extended with block extents.
E.g. a white block with 3 cells followed by a free block with 1 cell and a black block with 2 cells is encoded as:
10 00 00 01 11 00
The advantage is that only one or two bits for the first cell need to be flipped to change the status of a whole block: allocating a block only needs to set the block bit; marking a block only needs to set the mark bit.
Other metadata
Since cell indices don't start at zero, the first few bytes of the block and mark bitmaps can be used for other metadata related to the arena. At least 16 bytes can be used for arena management and for the gray stack pointers, since the minimum arena size is 64 KB.
Huge Blocks
Huge blocks are located in separate contiguous memory areas. Their size is always a multiple of the arena size and they obey arena alignment. The optimal size threshold to switch from regular block allocation to huge block allocation still needs to be determined experimentally.
There's no extra header in front of a huge block. Instead, all metadata (address, size, mark and gray bits) is stored in a separate hash table, keyed by the block address.
Block Allocator
The block allocator allocates space for a block either from an arena or as a huge block, depending on the requested size. The block allocator has different modes and switches between them on-the-fly, depending on fragmentation pressure and other feedback from the GC phases.
Huge blocks are allocated directly from the OS via the memory manager.
Bump Allocator
The standard block allocator is a high-speed bump allocator. It operates on a given memory space and allocates contiguous blocks of memory until it hits the end of the given space. It works best on large free memory spaces inside arenas.
The bump allocator only needs to set the block bit and 'bump' a pointer for each allocated block, which makes it very fast. This little amount of logic may even be inlined in performance-critical code.
The bump allocator is used as long as there remains a large-enough memory region and as long as fragmentation pressure is low.
Fit Allocator
If fragmentation pressure becomes too high, the allocator is automatically switched over to a segregated-fit, best-fit allocator with bounded search. This allocator is more costly than the bump allocator, but it's able to reduce overall fragmentation by 'filling the holes' in badly fragmented arenas.
The allocator is a segregated-fit allocator: requested allocations are divided into bins, according to their size class. Size classes start with multiples of the cell size and switch over to powers of two for bigger sizes. Each bin is the anchor of a list of free blocks in that size class. Initially all bins are empty. To minimize startup delay and to avoid unnecessary work, the allocator builds up its data structures on the fly.
The allocator first tries a best-fit allocation for the requested size class. If the corresponding bin is empty, a short, bounded-effort scavenging phase is started that scans the block map for isolated free blocks and links them into their corresponding bins.
If this doesn't turn up a best-fit allocation, the allocator degrades to a first-fit allocator, splitting up candidate blocks in a limited number of higher size classes. If none are found, it falls back to the bump allocator, possibly allocating from a newly created arena.
The allocator is adaptive: if the miss rate of the first-fit allocator is high, more higher size classes are subsequently searched. If the hit rate of the best-fit allocator gets better, this limit is reduced again.
After fragmentation has been reduced below a certain threshold, the allocator is switched back to the bump allocator.
Mark Phase
Marking of all live objects is performed iteratively, using advanced, cache-optimized data structures to hold the objects that are to be marked.
Write Barrier
The write barrier only has to check for the gray bit of objects stored into. This is a very fast test and it triggers only if the gray bit is not set (which is rare).
If the write barrier is triggered, white objects are turned light-gray and black objects are turned dark-gray. Dark-gray objects are additionally pushed onto a fast sequential store buffer (SSB).
Light-gray objects don't need to be pushed onto the SSB, but that requires checking the mark bit. This can be avoided, if performance of a triggered barrier becomes an issue. The check may be done on SSB overflow instead. When the collector is paused, the check for the mark bit can be completely avoided, since there can't be any black objects.
Sequential Store Buffer
A sequential store buffer (SSB) is a small buffer which holds the block addresses of objects that triggered the write barrier. It always has at least one slot free, so the overflow check can be done at the end.
If the SSB overflows, it's emptied by converting the stored object addresses to cell indices and pushing them onto the corresponding gray stacks. This may involve multiple allocations and other overhead.
The advantage of the two-step process is the relatively low cache pollution due to the SSB while the mutator is running.
Gray Stack
Every arena with traversable objects has an associated gray stack which holds the cell index of all of its gray objects. Memory for gray stacks is allocated and grown on demand and need not be part of the arena itself. The stack starts with a sentinel and grows downwards.
When an object is marked dark-gray, it's pushed onto the gray stack for the corresponding arena.
To improve cache access locality, the gray stack of each arena is processed separately. Objects removed from the gray stack are turned black before the traversal. The traversal may mark other objects, which may be located in different arenas. But processing always continues with the current arena until the gray stack is empty.
Gray Queue
The gray queue holds arenas which have a non-empty gray stack. The gray queue is a priority queue, ordered by the size of the per-arena gray stack. This ensures the largest gray stacks get processed first. A binary heap is used to implement the priority queue. It behaves mostly like a stack (LIFO) for elements with the same priority.
The gray queue is processed iteratively, always removing the highest priority arena and processing its gray stack. The mark phase ends when the gray queue is empty (and the SSB is emptied, too).
Sweep Phase
The sweep phase only needs access to the block and mark bitmaps of each arena. It can be performed separately for each arena.
There's no need to access the data area of an arena at all! This is a major advantage over most other GC layouts, because it doesn't bring neither live nor dead object data back into the cache during the sweep phase.
Bitmap Tricks
The special layout of the block and mark bitmaps allows use of word-wise parallel bit operations to implement the sweep:
A major sweep frees white blocks and turns black blocks into white
blocks: block' = block & mark mark' = block ^ mark
A minor sweep frees white blocks, but keeps black blocks:
block' = block & mark mark' = block | mark
Another convenient property of the bit assignments is that
arithmetically comparing a block word with a mark word gives the status
of the last block which starts in this word: block' < mark' => free
Propagating the 'free' status across words allows coarse coalescing of
free blocks, which can be combined into the sweep.
All of this works for any word size: SIMD operations can be used to work in parallel on 128 bits, i.e 2 KB worth of cells at a time.
The sweep phase operates only on 1/64th of the total memory and is able to use the full cache or memory bandwidth, because memory accesses are strictly linear. This makes the sweep phase ultra-fast compared to other GC algorithms.
Special Considerations
Stacks
Strings
Weak Tables
Finalizers
Object Layout
Object Tags
Performance Optimizations
Cache Effects
Branch Prediction
Data Structures
Bump Frontier
Segregated Traversal
Questions?
Add your questions here and I'll try to clarify. --Mike
Q: In the quad-color system, after a sweep, why not turn black into light-gray instead of black becoming white?
A: Because black to light-gray requires changing the "gray" bit which is stored locally in every object (thus costly to change for-all).
Q: Would it be possible to set a maximum memory limit for the new allocator, for proper sandboxing support?
A: Yes, the built-in memory managers have a configurable memory limit. The granularity is the arena size. You can plug in your own memory manager for more complex scenarios.
Q: When do you (Mike) plan to write the missing parts of this page? (I'm mostly interested in the "Performance Optimizations" part)
A: When I get around to it ... :-)
Q: Will the new gc support the full 64-bit address space?
A: Storage layout of GC references in tagged values is an orthogonal concern.
Q: I like the quad-color mark/sweep, but I believe it needs two changes so that black is consistently "reachable" and gray is consistently "dirty" (needs scanning):
- the push arc from white should go to black, not dark gray. It's bad to touch the object simply because you found a pointer to it, when the actual marking from that object may be some time in the future.
- there should be a self-arc for pop from black to black. Alternatively, insert a new state between white and black, which is also black and represents "clean, known to be reachable, but not yet marked from (on the mark stack)". push from white goes to this new state, pop goes to the existing black node which represents "clean, known to be reachable, already marked from (or in progress). The gray flag in the object should be cleared (if set) after it is removed from the mark stack, but before any embedded object pointers are pushed onto the mark stack.
A: All objects accessed by the mutator are reachable, of course -- at that point in time. But that's inconsequential. Reachability is ultimately determined by the collector. And this is just a snapshot at the end of one run. The objective of a garbage collector is to free definitely unreachable objects from time to time, not to continuously update the exact states of every object.
The push arc from white to dark gray is for the variant that moves the barrier forward (see the tri-color algorithm). This is only interesting for a few cases (not for tables). It can't go to black, as this would require an invocation of the traversal phase of the collector directly from the mutator, which is a really bad idea.
What you're describing is already solved by the gray states. Except with a different definition, based on collector time, not mutator time.
Q: this doesn't seem to be the whole story: "The write barrier doesn't need to access the mark bitmap, which avoids polluting the cache with GC metadata while the mutator is running.". True, if the gray bit is already set. But if the gray bit is clear then not only does it need to be set, you also then need to check the black bit and IFF it is set then push the object onto the mark stack. e.g.
if (!obj->grey) setGrey(obj);
void setGrey(obj){
obj->grey = true;
if (isBlack(obj)){
// if black state has been split as suggested above, also
// need to check that it's not already on the mark stack
push(obj);
}
}A: There's no need to access the mark bit for the fast path, i.e. when the write barrier doesn't trigger.
As described, the write barrier hardly ever triggers in practice. And if it triggers for a black object, this means we're in the short period at the end of a GC run, where the incremental collector races against the mutator. That's an even more rare occurence and then it doesn't really matter that the push is initiated by the mutator, since the GC metadata is in-cache, anyway.
The check for the mark bit in the slow path can be avoided, too. See the description of the write barrier in the mark phase.
There's never a need to check whether an object is already on the gray stack, since it'll never get to that part of the code, if the gray bit is already set.